<<<Part 1
Edge Picking
How we position the pick in relation to the strings can have a big effect on how fluidly we can play. One option has the pick parallel to the guitar string, as seen here.

(Note: In the above photo I don’t mean to imply that you move you pick in the directions of the arrows, simply that the pick is parallel to the string.)
That option is a good way to get a nice solid pick attack but it does slow you down as the pick is “fighting” to get over the string. For a smoother technique it makes sense to turn the pick either upward or downward as seen in the photos. With the pick turned in this manner the pick glides more smoothly over the string. The exact amount you want to turn it is open to experimentation; I’ve heard 45 degrees often recommended. (Shawn Lane, a noted speed picker, seems to have put his pick near a 90 degree turn.)
Upward pick turn

Downward pick turn

As noted, we have two options: aiming the pick up or aiming it down. Years ago, I fell into a downward turn, such that that my pick-holding thumb slightly points to the floor. (I don’t play with a 45 degree turn as mentioned above though I occasionally experiment with it. I’m probably around 30 degrees or so.) Is downward better than upper? I dunno… it probably depends on the person. I would advise trying both and decide what feels comfortable. I’ve been experimenting lately playing with an upward turn and it has a certain appeal. It has less forceful sound than my downward edge picking which lends a certain elegance.
Pick Slanting
First, a caveat. You will often see people use the term “pick slanting” to describe what I described above as edge picking. Hopefully these terms will settle as this confused me for a while.
I mentioned Troy Grady in part one and he’s really the guy that brought to light the concept of pick slanting (though everyone does it to some degree.) To grasp the concept, first envision a plane (a geometric plane, not a flying machine) that exists similar to a piece of paper lying flat against your strings. When you play, your pick could travel along this plane to pluck notes but it wouldn’t work well as your pick would just brush against the strings. To get greater attack it makes more sense to tilt that plane down (so that the pick travels towards the guitar during a pick downstroke) or up (so that the pick travels away from the guitar during a pick downstroke)*. If you follow a downward plane we call that downward pick slanting. If you follow an upward plane we call it… you got it: upward pick slanting.
*To makes things even more complex let’s acknowledge that we don’t really swing the pick in a flat plane but more of a curve. Nonetheless, thinking in planes is a good enough for our purposes.
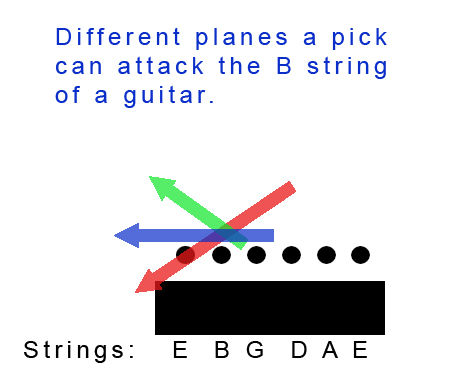
The problem here, as Grady points out, arises in certain situations when you are switching strings. Let’s say you tend to downward slant your pick and you are doing a three note per string descending scale starting on the 1st string. You alternate pick, starting from a downstroke, so you end the first three notes on a downward slanted downstroke, somewhat underneath the strings. So to get to that 2nd string you need to “string hop” (a Grady term) over the 1st.

Now if you had been upward slanting your pick, you would not have this problem. With an upward slant, at the end of these first three notes your pick would be high enough above the strings to have a clear plane of attack for the note on the 2nd string.
When do you use downward slanting and when upward? Basically when you get to the point where you will switch strings you want a straight plane of attack to the next string. But this plane will vary depending on whether you use strict alternate picking (every downstroke followed by an upstroke) or economy picking (two down or upstrokes in a row when efficient) or some combination of the two (as I do.) Here’s a couple of scenarios (They all presume you are starting with a downstroke.)
- If you are picking an odd number of notes on a string and then going to a higher string (as in an ascending scale) and using economy picking then use downward pick slating. If you are using strict alternate picking, use upward pick slanting.
- If you are picking an odd number of notes on a string and then going to a lower string (as in a descending scale) and using economy picking then use upward pick slating. This would still be true with alternate picking.
- If you are picking an even number of notes on a string and then going to a higher string (as in an ascending scale) then use downward pick slanting. (If you’re picking every note then you have to use alternate picking here. However, you could pick the first note, hammer on the second and then hit the next note on the new string with a continuation of the downstroke, e.g. economy style. You see that sort of thing in sweep picking.)
- If you are picking an even number of notes on a string and then going to a lower string (as in an descending scale) then use downward pick slanting. Except… well, you could do something like use an upward slant, pick the first note with a downstroke, the next note with an upstroke and then continue that stroke to hit the note on the next string. You will have a clear plane of attack because of the upward slant (which at this point is going downward.) I find this very uncomfortable but that could be just me.
At the end of the day, it’s a matter of figuring out how give the pick a clear plane of attack when at string hopping juncture. Of course, there are other ways to deal with the challenge of avoiding string hopping. You can, as mentioned in Part 1 of this article, use pull-offs and hammer-ons so that your pick ends up in the desirable position. (My understanding is that this is what Yngwie Malmsteen does.)
I know; it’s a lot to think about.Working out licks with this level of precision makes the most sense for licks that you repeat a lot. For more free flowing solos you can’t be considering all these factors in real time. However, it stands to reason that as you apply this logic to your playing it will start to creep into your improvised lines.

4 thoughts on “A Survey of Guitar Picking, part 2”